| March 2004 Index | Home Page |
Editor’s Note: This is a detailed and technical study. It discusses design issues in depth as they relate to the subject matter, learning objects, and best practices in instructional design, teaching, and learning.
Design Issues Involved in Using Learning Objects for Teaching a Programming Language within a Collaborative eLearning Environment
Jinan Fiaidhi and Sabah Mohammed
Introduction:
Collaboration and sharing are well-established traditions in higher education. Recently the open source model based on XML let academics build their collaborations upon the concept of learning objects. With learning objects one can develop reusable high quality educational learning contents. Learning objects are increasingly seen as key to a technology-based revolution in education and training — even to an emerging global knowledge economy.
An international effort is underway to formulate standards that will enable their exchange, and the topic is popular in many journals and at conferences, e.g.
eduSource Project http://www.edusource.ca/
MERLOT (www.merlot.org)
NSERC Task force on Virtual Universities and eLearning (http://www.nserc.ca/programs/taskforce_e.htm)
POOL Learning Portal (www.canarie.ca)
IEEE Learning Technology Journal (http://lttf.ieee.org/learn_tech/issues/january2003/index.html)
BlueJ utilities (http://java.sun.com/features/2002/07/bluej.html)
CAREO http://www.careo.org/
ED-MEDIA 03 Conference (http://www.aace.org/conf/edmedia/symposium2003.htm).
The major advantage of the learning objects is that it has an open source/reusable format that enables both facilitators and students actively construct/modify knowledge rather than are being taught centrally by a static core material. Unfortunately, this advantage is greatly limited by the current available system for locating learning object or what is known as the “silo model” (Downs, 2003). On the silo model, resources are not designed or intended for wide distribution. Rather, they are located in a particular location, or a particular format, are intended for one sort of use only. The original vision of learning object should encompasses beside the reuse and exchange of learning contents the ability to search, collaborate and distribute these contents among multiple educational settings, instructors, courses, and institutions. Certainly, the issue of reusability and personalization of learning objects allows learners with different requirements to learn what they need, in the style, format and speed, which they prefer.
However, sharing such learning objects is another important issue. If we accept the premise that institutions will share learning materials, then we need to ask, what will they share? The answer that intuitively offers itself is: courses. Why, then, would institutions not share these courses? To a certain degree, they already do so. Most colleges and universities define course articulation policies, whereby a course completed at one institution is accepted for credit at another institution. The assumption is this: that there are thousands of colleges and universities, each of which teaches popular programming languages such as “Java Programming”. And each Java course in each of these institutions describes the same concepts (e.g. polymorphism, inheritance, class, object, etc). Moreover – because the properties of these concepts remain constant from institution to institution – we can assume that each institution’s description of such concepts is more or less the same as each other institution. What we have, then, are thousands of similar descriptions of identical Java concepts.
The aim of this article is to investigate the possibility of adopting the notion of Learning Objects for constructing a collaborative eLearning system for teaching and learning Java programming as well as for providing an environment for collaborative programming (e.g. extreme programming). Actually one of the major problems of bringing students to the same level of understanding in a short period of time is the lack of an effective communication mechanism between instructor-student and student-student to share crucial knowledge at the right time.
Students often misunderstand concepts and thus apply them incorrectly; which leads to hours of wasted time spent on debugging logically incorrect code. By the time students get help it is either too late or there is little opportunity for the instructor or TA to intervene. According to Anderson (Anderson, Kanuka, 1997) the facilitators of any professional development activities have a responsibility not only to provide information but also to assist professionals in developing a critical and analytical way of considering knowledge, to provide opportunities for professionals to practice using their judgment skills, and to assist professionals in developing new knowledge based on practice. The best way to facilitate this kind of learning is through the rich resources of practical knowledge acquired by other professionals in a collaborative environment (Cervero, 1988).
This article describes an approach to a content creation and delivery mechanism for a Java programming course. This approach is based on the concept of creating a large repository of Java learning objects, each of which consists of the core material, code examples, supplementary notes, and review questions. A learning object will be uniquely described by a XML document and presents an interface for future search, retrieval and updating, as well as for potential connection to external assessment tools.
This article is a description about an ongoing development project at Lakehead University to create a collaborative eLearning environment for teaching and learning Java programming using the notion of learning objects. Various design issues been investigated for this purpose including the structure of Java Learning Objects and the Learning Objects Messanger Engine. Particular attention has paid for techniques required for searching for relevant learning objects from the various learning objects repositories on the Web. Three techniques have been found necessary for effective searching of learning objects based on collaborative ontology, query expansion and relaxation.
Learning Objects Realization and Standardization:
Learning objects (or RLO - reusable learning object) have been the hype of the elearning industry since 2000 (Hodgins, 2000). They have been hailed as the future reality of learning...and as idealistic, but unattainable view for education. Separating the hype from reality is still an ongoing activity. There are massive research efforts for describing, cataloging and tagging such learning objects. These tags provide descriptive summaries intended to convey the semantics of the object. Together, these tags (or data elements) usually comprise what is called a metadata structure.
Although learning objects are conceptually appealing, exactly what constitutes a learning object in practice has been unclear. In the past, different vendors have had different ways of instantiating the notion of a learning object and different ways of enabling learning objects to communicate information about the learner. For many researchers (Darlagiannis, et. al. , 2000), learning objects can be viewed based on the notions of Object Oriented Programming (OOP) - a programming term referring to the creation of segments of code that can be incorporated and reused in different areas. The view is that if learning is designed properly, each object will be a self-contained "piece" of learning. In this particular view, Java programming environment and many of its supporting tools can be considered as the basic infrastructure for any collaborative eLearning system.
The popularity of the Web is another encouraging factor which has greatly increased the availability of high bandwidth networking, making real-time collaboration feasible. In addition to network bandwidth, collaborators must also have compatible software. Java facilitates this by allowing software to be delivered over the web and executed on a variety of platforms without modification. Java also includes component support in the form of the JavaBeans component architecture (EJB). BeanBox, Sun's reference JavaBeans builder tool, provides an example of a simple standard environment for editing and connecting beans. Indeed using the EJB architecture we can build collaborative environments such as Sieve (http://linc.cs.ut.edu/Sieve).
Also we can use many Java APIs that can help in allowing the control and synchronization of distributed data such as Java Shared Data Toolkit(JSTD), Collaborative AWT (C-AWT), and Java Multimedia Framework(JMF) to build collaborative systems such as Habanero (Chabert, et al, 1998) and JAMM (Kuhmünch, et al, 1998). But such architectures prove to be restrictive, depends a lot on the APIs or EJB vendor implementation and utilities (Mahapatra, 2000) (Shirmohammadi, et. al., 2001). However, there are many notable attempts for solving these restrictions such as AdventNet SNMP API (http://www.adventnet.com/products/snmpapi4/) and CollabNet (http://www.collab.net) which is based on the extensible Java integrated development environment (IDE) as well as the JETS/JASMINE system which presents a more sophisticated transparent Java collaborative environment (Shirmohammadi, et. al., 2001) ( Shirmohammadi, et. al., 2003). Moreover, a variety of educational tools help in constructing a successful collaborative environment (See http://www.edutools.info/course/productinfo/index.jsp ).
As the eLearning landscape develops and matures, universal learning standards will become the conduit to connect global knowledge assets. Indeed searching the Web cannot the work of finding required educational objects. Simply because multimedia contents excluded, simplistic character matching mechanisms, and there is no way to search for educational aspects according to whatsoever category (age appropriate, user appropriate, or learning style appropriate).
Fortunately, and thanks to the efforts and cooperation of many standards organizations and the vendor community, there are now widely adopted standards that allow learning objects to be described, assembled, delivered, and tracked in a standardized way, regardless of their shape, size, or intended purpose. These organizations forms specialized groups to write specifications and to clarify issues such as: How should eLearning content be tagged? What fields should be required? And how can this information be communicated?
Once the specifications group compiles its work, it submits the proposed protocols to an official sanctioning body for standardization. A specifications group is an organization with common interests and purposes, and works to develop protocols - agreements - that the community can support. The most important groups which are writing specification models for Learning Objects are (E-com Inc, 2003):
Advanced Distributed Learning (ADL)
Aviation Industry CBT Committee (AICC)
Canadian Core Learning Resource Metadata Application Profile Initiative (CanCore)
Dublin Core Metadata Initiative (DCMI)
Institute of Electrical and Electronic Engineers (IEEE)
Instructional Management System (IMS) Global Learning Consortium
World Wide Web Consortium (W3C)
All these groups are developing standards for the new wave of eLearning systems and they agree that such new systems must fulfill the following requirements:
It should allow interoperability of content from multiple sources
It should allow interchangeability of content for transfer between sources
It should allow reusability of content within the same source
It should allow accessibility of content to search object repositories
It should have a separate communication Interface—how resources communicate with other systems,
It should have meta-data—how to describe eLearning resources in a consistent manner,
It should allow packaging—how to gather resources into useful bundles
Unfortunately, there is no universally agreed standard (FIAIDHI, MOHAMMED, 2003) (FIAIDHI, and MOHAMMED, 2003) among the above mentioned list. Instead, there are some universally agreed de facto, as opposed to formal, standards. De facto means that the specifications have been adopted widely, even before they are officially standardized. In this direction CanCore take the lead as the de facto standard (Friesen et al, 2002).
CanCore is a Canadian implementation of an emerging IEEE standard for educational metadata - the cataloguing and indexing information for digital learning resources. CanCore interprets and simplifies existing educational standards and protocols. CanCore allow educators, researchers and students in Canada and around the world to more easily search and locate material from any online repository of educational objects. These educational or learning objects can be as simple as individual web pages, video clips, or interactive presentations, or as comprehensive as full lessons, courses or training programs.
CanCore provides guidelines and interpretations that will reduce ambiguities and facilitate implementation and extension of metadata to meet the needs of a particular collection of resources while remaining searchable by users from afar. The CanCore Metadata Protocol is a streamlined subset of elements from IMS Global and is intended for the efficient and uniform description of digital learning resources. CanCore was developed by researchers in the CAREO and POOL projects sponsored by the Canarie Inc. eLearning Program. Since its initial introduction in 2000, it gains wide international followers.
The CanCore Learning Object Metadata Application Profile takes as its starting point the explicit recognition of the human intervention and interpretation that separates raw data management from the information or knowledge that can actually be "about" something. The Canadian Core Metadata Application Profile, in short, is a streamlined and thoroughly explicated version of a sub-set of the LOM metadata elements. The CanCore element set is explicitly based on the elements and the hierarchical structure of the LOM standard, but it greatly reduces the complexity and ambiguity of this specification. The CanCore specification includes many essential elements for all the essential educational categories.
Table 1 illustrates the basic CanCore elements. The general CanCore Schema provides 54 Elements in Total:
36 active elements
15 placeholder elements
3 reserved elements
Each element within the CanCore Schema can be described with 4 pieces of information:
Name: How the meta-data element should be spelled.
Explanation: The definition of the element.
Multiplicity: How many elements are allowed and whether their order is significant.
Type: Whether the element's value is textual, numerical or a date; and any constraints on its size and format.
Table 1: The CanCore Schema Elements

By using the CanCore elements and protocols, one can search for learning objects in the various repositories. CanCore as well as the other standards uses XML for describing both the learning objects as well as their metadata. XML offers a disciplined language for describing the various resources and provides a common set of elements that can be exchanged between multiple systems and products. There is one more magic reason behind agreeing on XML as an industry de facto which can be addressed as Data binding (Mahapatra, 2000), which allows a mapping of data from an XML document to a Java object, and then back again. Data binding starts with the assumption that your priority is business-driven, not XML-driven. Instead of elements and attributes, you want to work with people, names, addresses, and phone numbers. You want to dispense with XML and get to the data in the XML document, but you also don't want to have to wade through XML semantics to do it. For this reason, data binding allows a mapping from XML data (not structure) to business-driven Java classes.
These classes are user-defined, so they could be things like a Person class, an Address class, or a string field named city. Data binding APIs take care of converting elements' and attributes' data into these custom, business-driven types. There are numerous APIs that already allow some variant of this conversion: Jato, SAX, DOM, JDOM, dom4j, JAXP, etc. The list goes on and on; however, data binding has something unique that makes it worth delving into. The plus side of data binding is that XML data will look like Java objects which makes it easier for the Java programmer to manipulate and interact with that data. Such mappings are usually a two-way street in that they can also take a Java object and serialize it into XML. The negative side would be performance (by introducing some overhead) and the inherent incompatibility that exists among the different binding mechanism.
In this article, we are proposing a method that reduces the overhead of data binding and let Java source to be coded in XML. By capturing the mapping in a single place and then allowing JXML to handle the parsing, conversion, and generation, you save many lines of code and gain performance. Also we are proposing a browsing technique for learning objects based on their metadata as well as using some internal specific attributes of the required learning objects.
Using XML for Describing Structure of Java Learning Objects:
In this section we describe our initial thoughts arising from our intension to deliver a Java programming module to BSc students who are being taught through the medium of the Internet and among the various smart classrooms and labs at our Lakehead University Advanced Technology and Academic Centre(ATAC). According to the IEEE workshop on the “Practice and Experience with Java Programming in Education AICCSA’03” (Workshop on Practice, 2003) the educational use of Java, however, is still in its infancy at many educational institutions around the world, and therefore many of the pitfalls have yet to be discovered. The mode of teaching such proposed course is essentially seminar-based, with a heavy emphasis on the moderated discussion of module topics and coursework/assignments in a Virtual Classroom. This approach leads to a high degree of interaction between instructor and students, and, especially between students in the class, who collaborate to create a mutually supportive learning environment.
Previous eLearning systems represents merely communication tools and do not allow students to discuss a programming question in its own context. For example, a student cannot highlight or annotate specific passages in the course materials or the supplementary materials and cannot initiate a discussion thread around it. Another issue which can be identified with the core materials is that there is no easy and effective ways to interconnect major components of the course such as code examples, and review questions to the core content. Students in such courses are generally not capable of sorting out all information and figuring out what makes sense to them. Clearly the current use of core materials in programming courses is not effective because their static contents do not allow any kind of content personalization, enhancement or interaction. We believe that we can address some of these problems by creating a better knowledge transfer mechanism between the teacher and the student or the students among themselves. We will focus in this section on presenting the key Java programming concepts by utilizing learning objects (referred to us as Java Learning Objects). Addressing this aspect, we need to make sure that all course related material is organized into a basic repository of the information objects. The key components of the basic repository are core Java course content, Java code examples and review questions. Then instructors can create learning objects using the basic repository of information objects; and share them with colleagues and students. Also we need to be certain that all knowledge components are assembled under one unified and interactive environment.
However and as have been described in the last section, XML should be used for representing the Java learning objects. Surely XML can represent any datatype including the bytecode (Pentakalos, 2001) which will let us represent any Java .class module in XML. This can be done automatically by using Byteml API (http://byteml.sourceforge.net/main.html) or by using Jato API which converts XML documents into Java objects and back again (Krumel, 2001). This way of representation is quite restrictive for two reasons:
Projects needs to be represented using several XML files, and
Java source code and other textual materials can not be represented.
For this reason we believe that the facilitator need to assemble any Java project that he/she needs to explain its practical use in his/her course as a Java bean which can be converted to XML later using simple classes like BeanXMLMapping (Caroli, 2003) which have two methods. The "toXML():" generates the respective XML document String for the bean instance and the fromXML(): creates a bean instance for the XML document String. Generally, we assume that every Java Learning Object should include other essential programming elements. Figure 1 illustrates our imagination to the general architecture of the Java Learning Object.
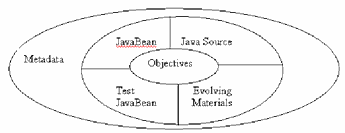
Figure 1: The architecture of Java Learning Object.
The issue of writing Java source code into XML can be treated effectively in two ways, either by using a very simplistic authoring language like srcML (Michael, Collard, and Marcus, 2002) or developing a syntax directed editor which according to Java Syntax schema the facilitator can insert the Java source within the XML code of the Java learning object (Simic, and Topolnik, 2003). The evolving materials module initially includes the facilitator description of a Java concept and it allow students to create personalized learning profiles and share them with others as well as creating an environment where students and facilitators can discuss course-related material. The facilitator and thereafter the students can use simple authoring toolkits like the LOM editor (Kassanke, and Steinacker, 2001) to edit any learning object evolving material. The Beans testing module is an environment which enables students to test the facilitator JavaBean by incorporating linkage to the Sun’s Java BeanBox http://java.sun.com/products/javabeans/software/bdk_download.html or by using the Bean-test API( http://www.rswsoftware.com). The meta data module provides all the external references and relations to the other learning objects and databases as well as the learning constraints and the internal structure of the learning object. The meta data must conform to one of the international standards. For the purposes of our discussion here, a Learning Object (LO) will be defined as a unit of instructionally sound content centred on a learning objective or outcome intended to teach a focused Java concept and it should follow the CanCore standard (www.cancore.org/schema.html). This will enable the resulted learning object to be used widely through the eduSource educational network (http://www.edusource.ca/) or the POOL learning portal (www.canarie.ca) (Richards, McGreal, and Friesen, 2002) (Hatala, and Richards, 2002). The objective module should be designed by the facilitator by setting guiding rules on the role of the learning object and its relations to the other learning objects.
Learning Objects Messenger
for discussions and exchange of learning objects:
As you might expect for any web-based application, XML can provide a standard, agreed upon format to transfer data over the Internet. In this respect XML is similar to a data format such as Comma Delimited or SDF file in the past. However, as a data representation format XML is also much more flexible than these old formats, because it can carry just about any kind of data. Most other text formats have been hampered by their limited ability to transport complex data like memo fields or binary data. XML is very flexible in what kind data it can carry.
However, establishing a communication and discussion platform within such environment is a different issue. In the past, such distributed applications have been treated using Java technology system with RMI. Or, perhaps some COM or CORBA objects resided on the server. The use of such technologies will not provide an open-source communication paradigm.
Alternatively, XML Web services are open and platform-independent. It is not important how the service is implemented underneath. With UDDI (Universal Description, Discovery and Integration), a system can publish all its services for all potential clients to discover. For this reason many XML-based messaging utilities have been introduced during the last few years which ranges between a Lightweight API (e.g. JML toolkit (http://java.sun.com/products/jms/) and a sophisticated XML messaging platform (e.g. ebXML (www.ebxml.org)). Most of these utilities comply with the standard XML Messaging specification of the W3C (http://www.w3.org/TR/xmsg/).
The Primary goals of the W3C XML Messaging specification are: to provide the ability to transport multiple documents and references to associated data objects within a single document (a message) and preserve their identity, to provide the ability to associate metadata with both the documents and the message without modifying the original document or schemas for those documents, and to provide the ability to transport non-XML data as a document within the message.
For our collaborative environment we are proposing the use of SOAP (Simple Object Access Protocol) which can implements all the required functionalities of discussion and message exchange (http://www.w3.org/TR/SOAP/). SOAP uses a standard lightweight JAXM API (http://java.sun.com/xml/jaxm/). This is useful because your application can then communicate across different platforms (since SOAP is XML-based, and therefore plaintext), and communicate with XML Web services. By utilizing SOAP, any system can use a Web service from any other system by communicating with XML-based messages. On either end, these XML messages can be converted to whatever format is necessary for the system to understand. SOAP message has the following general structure:
The SOAP envelope, represented by a <soap-env:Envelope> element.
The SOAP header (optional), represented by a <soap-env:Header> element.
The SOAP body, represented by a <soap-env:Body> element.
One or more body elements. This is the actual content of the message.
A SOAP Fault (if an error occurred), represented by a <soap-env:Fault> element.
Based on SOAP the sequences of communication events can be summarized as follows (see Figure 2):
The student creates and sends a SOAP message containing requests for one or more Java-based concepts.
The LOMBE receives the SOAP message containing the requests and processes it, extracting the names of the requested concepts. Errors are handled by the use of a SOAP Fault element.
The LOMBE searches for the requested concepts from the main LO repository or from the students collaborative LO repository. Again, if an error occurs, it will be trapped with a SOAP Fault.
The LOMBE creates and sends a SOAP message, containing the requested LO, back to the waiting student.
The student receives and processes the response message, extracting the required concept information. If the student would like to comment on the LO, then s/he can save a new copy of LO at his/her personal LO repository.
If no matching LOs been found a SOAP message is sent to the CanCore/eduSource registry service to search for external learning objects.
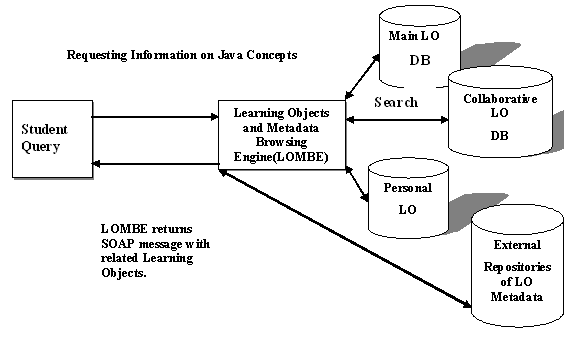
Figure 2: SOAP-Based Communication Infrastructure: The LOs Messenger.
Browsing and Searching for Learning Objects: Problems and Proposal
Many researchers believe that searching for learning objects should be straightforward via searching for a matching metadata (i.e. an XML document). This believe came from the fact that XML is a form of a database (Rizzolo, Mendelzon, 2001) and hence searching for an XML metadata should be as easy as querying a database. According to such believe, many organizations developed various searching engines for the XML databases of documents(e.g. Amberfish, IXIASOFT, Infonyte Query, XML Query Engine, Tamino, MLE, Ultraseek, SIM, X-Hive, Xdirect, Xset, fxgrep, Xtenint, and Lore).
As a "database" format, XML has some advantages. For example, it is self-describing (the markup describes the structure and type names of the data, although not the semantics), it is portable (Unicode), and it can describe data in tree or graph structures. It also has some disadvantages. For example, it is verbose and access to the data is slow due to parsing and text conversion. Actually an XML document is a database only in the strictest sense of the term.
On the plus side, XML technology provides many of the things found in databases: storage, query languages, programming interfaces, and so on. On the minus side, it lacks many of the things found in real databases: efficient storage, indexes, security, transactions and data integrity, collaborative access, triggers, queries across multiple documents, and so on. For this purpose, many surrounding technologies have been developed for treating XML documents as a database management system DBMS (e.g. DTD, XML schema, XQuery, XPath, XQL, XML-QL, QUILT).
However, we don't think that XML technology will solve "the search problem" alone at any time soon, although in the long run, XML will provide many of the benefits of database searching while still retaining the simplicity of plain text searching (FIAIDHI, MOHAMMED, and YANG, 2004). There are many programming and standardization issues involved and need to be addressed first. We are listing some of such issues that affect searching and browsing learning objects and their metadata:
XML Search Requires Collaborative Ontology: The roadmap to build the future Semantic Web is built around the universal XML communication model. The semantic web represents technologies for enabling machines to make more sense of the Web, with the result of making the Web more useful for humans. The hope is that the semantic web can alleviate some of the problems with the current web, and let computers process the interchanged data in a more intelligent way. In an open system like the Internet, which is a network of heterogeneous and distributed information systems (IS), mechanisms have to be developed in order to enable systems to share information and cooperate. This is commonly referred to as the problem of interoperability.
The essential requirement for the semantic web is interoperability of IS. If machines want to take advantage of the web resources, they must be able to access and use them. Ontology is a key factor for enabling interoperability in the semantic web (Berners-Lee, Hendler, Lassila, 2001). An ontology is an explicit specification of a conceptualization (Uschold, and Gruninger, 1996). It includes an explicit description of the assumptions regarding both the domain structure and the terms used = to describe the domain. Ontologies are central to the semantic web because they allow applications to agree on the terms that they use when communicating. Shared ontologies and ontology extension allow a certain degree of interoperability between IS in different organizations and domains. However there are often cases where there are multiple ways to model the same information and the problem of anomalies in interpreting similar models leads to a greater complexity of the semantic interoperability problem. In an open environment, ontologies are developed and maintained independently of each other in a distributed environment. Therefore two systems may use different ontologies to represent their view of the domain.
Differences in ontologies are referred to as ontology mismatch (Klein, 2001). The problem of ontology mismatch arises because a universe of discourse, UoD, can be specified in many different ways, using different modeling formalisms. In such a situation, interoperability between systems is based on the reconciliation of their heterogeneous views. How to tackle ontology mismatch is still a question under intensive research. A solution to the ontology mismatch problem should yield a collaborative ontology.
XML Search Requires Query Relaxation: As the Web becomes a major means of disseminating and sharing information and as the amount of XML data increases substantially, there are increased needs to manage and query such XML data in a novel yet efficient way. Unlike relational databases where the schema is relatively small and fixed, XML model allows missing structures and values, which make it difficult for users to ask questions precisely and completely. To address such problems techniques like query relaxation (Gaaster, 1997) can be used to enable systems to automatically weaken, when not satisfactory, the given user query to a less restricted form to permit approximate answers as well.
XML Search Requires Query Expansion: One of the strengths of XML is that it can be used to represent structured data (i.e., records) as well as unstructured data (i.e., text). For example, XML can be used in a hospital to represent (structured) information about patients (e.g., name, address, birth date) and (unstructured) observations from doctors. To take advantage of this strength, however, it is important to have tools and techniques that can work effectively with both kinds of data; it is in particular important to have XML query languages which select records from the structured part of an XML document and search for information in text. For instance, it should be possible to pose one query that finds all patients that are older than 45 years and have some specific symptoms. Hence, searching text-rich XML documents on the web or in a collaborative environment can be both rewarding and frustrating.
While valuable information can be found, typically many irrelevant XML documents are also retrieved and many relevant ones are missed. Terminology (e.g. tags, keywords) mismatches between the user's query and document contents are a main cause of retrieval failures. As a solution one can use query expansion (Cai, Rijsbergen, 2002). Expanding a user's query with related words can improve search performance, but finding and using related words is an open problem. One solution used for finding related terminologies is that each term is expanded to a disjunctive set of terms on the basis of term relationships pointed out by the collaborative ontology. If expansion to broader concepts is requested, only the immediate broader concepts are added, because that would probably expand the meaning of the query too far. If expansion to narrower concepts is requested, the terms are expanded to all immediate or indirect narrower terms. If associative expansion is requested, expansion is by one link in the association relationship. If expansion to instance terms is requested, the instance terms of all expanded concepts are included.
Currently the above problems have not been solved and there is no query language for XML which is fully standardized by WWW Consortium (W3C). However, there are several query languages for XML documents available from various vendors. For example XQL, XML-QL and Quilt (all accessible via http://www.w3c.org). For simplicity we recommend XQL to be the driving engine within our proposed Learning Objects and Metadata Browsing Engine (LOMBE). The reasons for choosing XQL can be summarized as follows: a) its grammar has already been standardized by W3C, and b) Application Programming Interfaces (API) for XQL are available in Java. It is important to note first, that XQL is used to query an individual XML page, and to return results from that page. It does not query many XML pages, and return combined results from them. In this direction, we are proposing the SAX API directly over a database, enabling XML tools to treat databases with a JDBC driver. That way, we can obviate the need of converting a database.
The proposed LOMBE can be viewed as integral search engine which generates/updates the collaborative learning objects metadata index by searching through the new learning objects created by each individual student/facilitator and also by using similar concepts suggested through the selected ontology similarity and merging algorithm. The LOMBE starts by allowing each student to enter the query using the traditional SQL format. The original query, then, will be reformulated using both query expansion and relaxation algorithms and the search will start by fetching the relevant concepts within the inverted index of the facilitator main LO database.
Also the LOMBE crawls through the repository of each individual student, and runs the XQL query off each LO which been referred by the collaborative index. At the end the LOS displays matched LO to the requester student. The LOMBE can upload the facilitator metadata and/or the collaborative metadata to the CanCore/eduSource registry for the wide use. Finally the LOMBE can be used to search and browse for external learning objects through the CanCore/edu registry panel. Figure 3 illustrates the architecture of such general collaborative XML search engine.
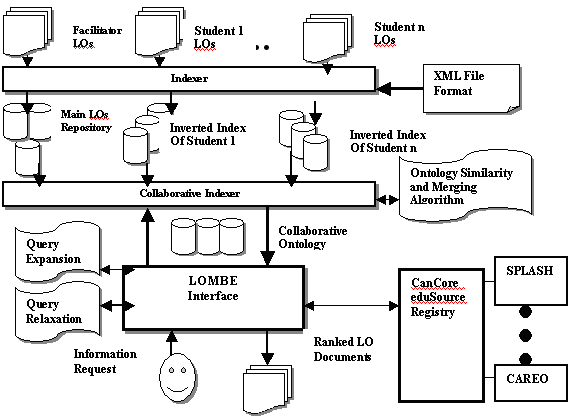
Figure 3: General structure of the LOMBE Searching and Browsing Engine.
The proposed components of the proposed Learning Objects Services modules can be summarized as follows:
The Indexer indexes and searches well-formed XML-based LOs, not necessarily be verified ones. This means that the system ignores DTD, even if it is provided.
Finite number of Java concepts, which we like to make searchable, must be identified well in advance to the indexing time. In addition and more importantly, the associations within LO’s structure from tag-paths to search fields must be defined in a setting file called XML File Format.
The indexer first interprets the Format file, then creates a set of necessary files, such as an inverted index, for each defined tag and textual tokens.
The collaborative indexer retrieves all the inverted indexes outputted by the indexer and produces a collaborative ontology metadata index through the use of suitable similarity and merging algorithm.
The LOMBE Interface enables peers to formulate a query, acceptable by the query engine, from the user's information request. The interface tunes the query to the common interest of the peer’s community via query expansion and also by using the collaborative ontologies as well as by finding the related tags via query relaxation. The interface searches both the facilitator and the collaborative repositories for matching learning objects. In case there is no direct searching outcome available within the collaborative environment, the search is put to the CanCore/eduSource registry to look for possible matching through the various available learning objects metadata repositories(e.g. SPLASH, CAREO, ALOHA). The output of the interface is a set of ranked LO documents. The interface also enables users to browse the Java course syllabus and click linkages to any learning object of interest.
Conclusions:
This article introduces some design principles needed to adopt and implements the notion of Learning Objects for teaching Java programming within a collaborative eLearning environment. It also shed the light on how to search for such learning objects at the collaborative environment and beyond.
References:
Anderson, T. and Kanuka, H. December 1997, New Platforms for Professional Development and Group Collaboration, JCMC 3. http://www.ascusc.org/jcmc/vol3/issue3/anderson.html
Berners-Lee, T. Hendler, J. Lassila, O., May 2001, The Semantic Web: A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities. (In Scientific American Online at: http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html
Cai, D. Rijsbergen, C. J. Van, April 08 – 10 2002, Automatic Query Expansion Based on Directed Divergence, International Conference on Information Technology: Coding and Computing, (Las Vegas, Nevada, USA).
Caroli, P. May 9, 2003, Still parsing to generate your JavaBeans' XML representation? Javaworld Online journal.
Cervero, R. 1988, Effective continuing education for professionals, San Francisco: Jossey-Bass Publishers.
Chabert A. et al, June 1998, Java Object Sharing in Habanero, Communications of the ACM, Volume 41, No. 6, pp. 69-76.
Darlagiannis, V. Ackermann, R. El-Saddik, A. Georganas, N.D. and Steinmetz, R. Oct. 2000, Suitability of Java for Virtual Collaboration, Proc. Net.Object Days 2000, (Erfurt, Germany).
Downes, Stephen 2003, Design and Reusability of Learning Objects in an Academic Context, USDLA Journal, Vol. 17, No. 1.
E-com Inc, January 2003, Specifications and Standards in eLearning Systems: Current Overview of Seven Models. http://demo.flexsite.net/templates/theorix_13_02_2002/standards.cfm
Fiaidhi, J. and Mohammed, S. 2003, Towards Developing Watermarking Standards for Collaborative eLearning Systems, Pakistan Journal for Information and Technology, 2(1).
Fiaidhi, J. Mohammed, S. and Faisal, K. April 2003, Developing Software Forensics Standards for Collaborative eLearning Systems, International Journal of Applied Science and Computations, Vol. 10, No. 1.
Fiaihdi, J. A.W. Mohammed, S. M.A. and Yang, L. 2004, On an Integral Approach for Searching XML Documents in a Collaborative Environment, Asian Journal of Information technology, Vol 3, No. 1, (Accepted for Publications).
Friesen, Norm 2002, CanCore: Metadata for Learning Objects, Canadian Journal of Learning and Technology,Volume 28, No. 3.
Gaaster, T., September-December 1997, Cooperative Answering through Controlled Query Relaxation, IEEE Intelligent Systems, Vol. 12, No. 5.
Hatala, M. and Richards, G. 2002, POOL, POND and SPLASH: A Canadian Infrastructure for Learning Object Repositories. Paper presented at the 5th IASTED International Multi-Conference Computers and Advanced Technology in Education (CATE 2002). Cancun, Mexico.
Hodgins, H. W. (Feb. 2000), Into the future of Technology and Adult Learning, White Paper, (http://www.learnativity.com/into_the_future2000.html).
IEEE, 2001 IEEE Learning Technology Standards Committee (LTSC) (2001) Draft Standard for Learning Object Metadata Version 6.1. ( http://ltsc.ieee.org/doc/)
Kassanke, S. and Steinacker, A. 2001, Learning Objects Metadata and Tools in the
Area of Operations Research, World Conference on Educational Multimedia, Hypermedia and Telecommunications EDMEDIA,Finland.
Klein, M., 2001, Combining and relating ontologies: an analysis of problems and solutions, In. proceedings of the 17th International Joint Conference on Artificial Intelligence IJCAI-01 Workshop: Ontologies and Information Sharing, (Seattle, USA).
Krumel, A. April 2001, Jato: The new kid on the open source block, Javaworld Online Journal, http://www.javaworld.com/javaworld/jw-04-2001/jw-0413-jato2_p.html
Kuhmünch et al, C. 1998, “Java Teachware - The Java Remote Control Tool and its Applications”, Proc. ED-MEDIA'98.
Mahapatra, S. August 2000, Programming Restrictions on EJB, JavaWorld Online Journal, http://www.javaworld.com/javaworld/jw-08-2000/jw-0825-ejbrestrict.html
McLaughlin, B. May 2002, Java & XML Data Binding, (ISBN 0-596-00278-5, O’Reilly Pub. Co.).
Michael, L., Collard, I. J., and Marcus, M. A. 2002, Supporting Document and Data Views of Source Code, ACM DocEng’02, (November 8-9, McLean, Virginia USA)
Pentakalos, O. September 28, 2001, Transfer binary data in an XML document, Javaworld http://www.javaworld.com/javatips/jw-javatip117_p.html
Richards, G. McGreal, R.and Friesen, N. June, 2002, The evolution of learning object repository technologies: Portals for on-line objects for learning (pool). In E. Cohen & E. Boyd (Eds.), Proceeding of the IS2002, Informing Science +IT Education Conference, (pp. 176 - 182). Cork, Ireland: IS2002.
Rizzolo, F. Mendelzon, A. 2001, Indexing XML Data with ToXin, Fourth International Workshop on the Web and Databases, (Santa Barbara, CA.).
Shirmohammadi, S. El-Saddik, A. Georganas, N. D. and Steinmetz, R. 2003, JASMINE: A Java Tool for Multimedia Collaboration on the Internet. Multimedia Tools and Application 19(1): 5-28.
Shirmohammadi, S., El-Saddik, A. Georganas, N. D. and Steinmetz, R., 2001, Web-based multimedia tools for sharing educational resources. ACM Journal of Educational Resources in Computing 1(1): 9
Simic, H. and Topolnik, M. 2003, Prospects of encoding Java source code in XML, paper published on ConTel: 7th International Conference on Telecommunications, (June 11-13, Zagreb, Croatia, 2003). http://www.javaworld.com/javaworld/javatips/jw-javatip138.html
Uschold M. and Gruninger, M, June 1996, Ontologies: Principles, Methods and Applications. Knowledge Enginerring Review 11(2).
Workshop on Practice and Experience with Java Programming in Education Co-located with the ACS/IEEE International Conference on Computer Systems and Applications, (Tunis, Tunisia AICCSA, July 18 2003)
About the Authors
Jinan A. W. Fiaidhi is Associate Professor position of Computer Science at Lakehead University. She received her B.Sc. in Applied Statistics from AlMustansriyah University (1976), and her graduate degrees in Computer Science from Essex University (1983), and Ph.D. from Brunel University (1986). From 1986-1996, Dr. Fiaidhi was Assistant/Associate Professor of Computer Science at the University of Technology. In 1993 she became Chairperson. In 1996-1997 she was Associate Professor of Computer Science at Philadelphia University. In 1997 she was Associate Professor at Applied Science University and in 1999 became Full Professor.
In 2000-2001 she was Professor of Computer Science at Sultan Qaboos University.
Dr. Fiaidhi co-authored four text books in Compilers, Artificial Intelligence, Java Programming and Applied Image Processing and published in 65 refereed publications. In 1997 and 1998 she chaired scientific committees international conferences on Computers and their Applications.
Dr. Fiaidhi’s research interests include Learning Objects, XML Search Engine. Software Forensics, Java watermarking, and collaborative eLearning systems, Software Complexity. Dr. Fiaidhi is on the editorial boards of the International Journal of Computers and Information Sciences, Jordanian Journal of Applied Sciences, International Arab Journal of Information Technology, Asian Journal of information Technology, and Pakistan Journal of Information and Technology. Dr. Fiaidhi is a member of the British Computer Society, member of the ACM SIG Computer Science Education, Information Society Professional of the Canadian Information Processing Society and member of the International Forum of Educational Technology
She can be contacted at the Department of Computer Science, Lakehead University, Ontario P7B 5E1, Canada or by email at jinan.fiaidhi@lakeheadu.ca.
Sabah M.A. Mohammed is Associate Professor, Department of Computer Science, Lakehead University, Ontario P7B 5E1, CANADA. Dr. Mohammed received his B.Sc. in Applied Mathematics from Baghdad University in 1977, his MSc degrees in Computer Science from Glasgow University in 1981, and Ph.D. from Brunel University in 1986.
Since late 2001, Dr. Mohammed is an Associate Professor of Computer Science at Lakehead University. Formerly, from 1986-1995, Dr. Mohammed was an Assistant/Associate Professor of Computer Science at Baghdad University. In 1996-2001, he served as Chair of Computer Science at four different universities: Amman University (1995-1996), Philadelphia University (1996-1997), Applied Science University (1997-2000), and Higher College of Technology(2000-2001).
Dr. Mohammed has co-authored four text books in Compilers, Artificial Intelligence, Java Programming and Applied Image Processing, published over 70 refereed publications, was the MSc advisor for 14 students and 1 PhD student, and has received research support from a variety of governmental and industrial organizations. Dr. Mohammed has consulted for a variety of organizations. Dr. Mohammed organized two international conferences on Computers and their Applications during 1997 (Philadelphia University) and 1998 (Applied Science University) as well as a Regional Symposium on eEducation during 2001 (Higher College of Technology).
Dr. Mohammed’s research interests include image processing, artificial intelligence and fuzzy logic. Dr. Mohammed is also on the editorial boards of the Jordanian Journal of Applied Sciences, Pakistan Journal of Information and Technology, International Arab Journal of Information Technology and the Asian Journal of Information Technology. Dr. Mohammed is a member of the British Computer Society, voting member of the ACM, and Member of IEE.
Contact him at: sabah.mohammed@lakeheadu.ca, Tel: 1 807 343-8777 Fax: 1 807 343-8023