| March 2006 Index | Home Page |
Editor’s Note: In London, Peter Oriogun used content analysis of online transcripts to study quality of interaction, participation, and cognitive engagement. New tools developed by the London Metropolitan University were used to improve inter-rater reliability.
Content Analysis of Online Transcripts:
Measuring Quality of Interaction, Participation and Cognitive Engagement
within CMC Groups by Cleaning of Transcripts
Peter K Oriogun
Abstract
In this article the author addresses a number of issues relating to inter-rater reliability of computer-mediated communication (CMC) message transcripts. Specifically, recoding of a semi-structured CMC message transcripts within the categories of a recently developed inter-rater reliability method called a Transcript Reliability Cleaning Percentage (TRCP) for measuring the level of online groups engagement with respect to ‘participation’ and ‘interaction’. The author used another relatively new approach (both methods developed at London Metropolitan University), called SQUAD as a framework within which to measure the cognitive engagement of online groups. A case study is presented to examine online participation, interaction and cognition within groups using the TRCP inter-rater reliability method and the SQUAD approach. It is argued in this article that it is possible to obtain 100% inter-rater reliability agreement when using ‘message’ as the unit of computer-mediated communication (CMC) transcript analysis. It is further argued that it is time consuming to perform such exercise, and that this is the reason that few researchers using quantitative content analysis of CMC transcripts have published results derived from a second content analysis. It is claimed that the experiment conducted in this article with TRCP inter-rater reliability method has informed the SQUAD approach to online discourse.
Introduction
In this paper the author adopts a recently developed method for cleaning online transcripts called a Transcript Reliability Cleaning Percentage (TRCP) within another recently developed and validate semi-structured approach to CMC discourse called SQUAD (Oriogun, 2003b), as a framework to measure software engineering students’ interaction, participation and cognitive engagement within online groups.
According to (Oriogun, 2003a; Oriogun and Cook, 2003) the TRCP inter-rater reliability method defines Participation as extending the suggestion for criteria for grading graduate-level student participation in a CMC classroom as reported in Hutton and Wiesenberg (2000). The criteria are as follow:
Evidence of completion of readings
Relevance: the student’s comment moves the discussion forward
Logic: the points are expressed and elaborated well
Insight: the points reflect a creative or novel approach
Referencing other students’ notes in their own comments
Acknowledging the work of others: agree, debate, question, synthesize, or expand
Appropriate etiquette (no ‘flaming’ or sexist/racist remarks)
In the same articles (Oriogun, 2003a; Oriogun and Cook 2003) Interaction was defined along the lines of Fahy (2001), where the meaning of the interaction must be something obvious and constant within the transcripts, and it reflects the interaction of the readers’ knowledge and experience with the text in the message. Irrespective of what the writer intends, what the readers understand is based on the interaction between the message and the readers’ experience, knowledge, and capability for understanding the topic. TRCP inter-rater reliability method further extends Fahy’s definition, by offering the following criteria for grading graduate-level student interaction in a CMC discourse:
Low Interaction: resolving conflicts within the group
Medium Interaction: offering alternative solutions to group problems and offering to deliver relevant artifacts for the group’s common goal
Active Interaction: delivering relevant artifacts for the group’s common goal
In this article, the author empirically validates the Transcript Reliability Cleaning Percentage (Oriogun, 2003; Oriogun and Cook, 2003) using the SQUAD approach as a framework. Furthermore, the author will use the method suggested by (Oriogun, Ravenscroft and Cook, 2005) to realise the cognitive engagement attributed to online groups using the Practical Inquiry Garrison et al (2001) model as a framework for the case study presented, using the alignments suggested by one of the developers of the Transcript Analysis Tool (TAT) Fahy (2002) at sentence level to assess students’ cognitive engagement within online groups as suggested by (Oriogun, Ravenscroft and Cook, 2005).
Garrison et al. Cognitive Presence: Community of Inquiry Coding Template
As content analysis protocols that exist today do not cater for all of the constructs that researchers would like to study, consequently, many researchers develop their own procedures. For example, Rourke and Anderson (2004) reported that when Garrison et al. (2000) adopted their theoretical model for critical thinking in an empirical study, they were unable to find any evidence of ‘resolution’ when they coded one-third of the transcripts as ‘other’, and coded the remaining two-thirds as ‘exploration’ and ‘integration’. This led to the development of the Practical Inquiry model (PI model) Garrison et al. (2001). Content Analysis was used to investigate ‘messages’ as unit of analysis in the PI model.
In order to capture the complexities of online learning, Anderson, Rourke, Garrison and Archer (2001) adopted a previously developed model (see Figure 1 below). The quadrants of the model correspond to categories of cognitive presence indicators. In the model, there is also a possibility of cognitive conflict Piaget (1928), whereby cognitive development requires that individual encounter others who contradict their own intuitively derived ideas and notions. Cognitive Presence can be summarised as having four phases of critical thinking, namely, a Triggered Event deals with starting, inviting or soliciting a particular discussion; the Exploration phase is when information is exchanged between the learning participants; the Integration phase is when participant learners construct meaning and propose possible solutions; and finally, the Resolution phase is when proposed solution(s) is/are tested out (Garrison et al., 2001:11).
The method proposed by Garrison et al.’s (2001) for detecting triggering events, exploration, integration and resolution involved classification of the four categories at message-level. By message-level, we mean a unit of online transcript analysis that is objectively identifiable; unlike other units of online transcript analysis, the message-level unit allows multiple coders to agree consistently on the total number of cases Oriogun, Ravenscroft & Cook (2005).
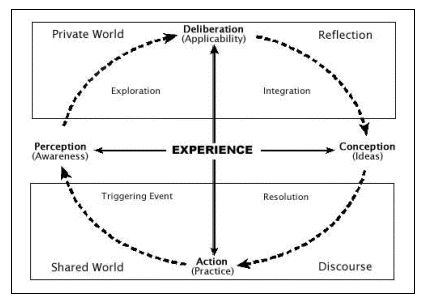
Figure 1. Practical Inquiry Model (Garrison et al. 2001)
Introducing Fahy’s TAT Alignments
Fahy et al.’s (2000) developed an analytical tool for measuring online transcripts, called Transcript Analysis Tool (TAT) based on Zhu’s (1996) earlier work, which operates at a sentence-level of analysis for the comparison of the frequencies and proportions of 5 categories or sentence types in a particular dataset. After Fahy (2002) examined the Practical Inquiry model, he realised that the categories of the TAT might be capable of being aligned with the phases in Garrison et al’s model, the resulting alignments reflecting different assumptions about the linguistic and social behaviour associated with the model’s phases. From three such alignments an analysis was produced, allowing a comparison of both the analytic processes involved and the resulting richness of the insights provided. In aligning the TAT with the four phases of cognitive presence model (see Figure 1), interpretation was required. The TAT categories were produced, based upon different assumptions regarding what interactive behaviour is apparent in Garrison et al’s (2001) phases of cognition (Fahy, 2002). Full detail on the TAT categories and alignments can be found in (Fahy, 2002) and (Oriogun, Ravenscroft and Cook, 2005).
Literature Review of Inter-rater Reliability of CMC Content Analysis
Literature Review on the variables used for content analysis of online transcripts revealed that in the context of CMC research, five variables that tend to be investigated are participation, interaction, social, cognitive and meta-cognitive elements of online discourse. For example, Henri (1992) identified these five elements as key dimensions for the analysis of online discussion. She used thematic as a unit of analysis. Weiss and Morrison (1998) investigated critical thinking, understanding/correcting, misunderstanding and emotion using thematic and message as units of analysis. McDonald (1998) used thematic as a unit of analysis during the investigation of six variables, namely, participation, interaction, group development, social, cognitive and meta-cognitive elements. Hara, Bonk and Angeli (2000) used paragraph as a unit of analysis for the same five variables as Henri (1992). Fahy et al. (2000) investigated interaction, participation and critical thinking, using sentence as a unit of analysis. Oriogun (2003a) used message as a unit of analysis when he investigated participation and interaction when he first proposed his Transcript Reliability Cleaning Percentage (TRCP). The theoretical basis for the TRCP inter-rater reliability method was published recently (Oriogun and Cook, 2003).
The SQUAD Framework
According to Oriogun (2003b), the SQUAD framework to CMC discourse adopts problem-based learning (Barrows, 1996; Bridges, 1992; Oriogun et al, 2002) as an instructional method with the goal of solving real problems by:
Creating the atmosphere that will motivate students to learn in a group setting online (where students are able to trigger a discussion within their respective groups);
Promoting group interactions and participation over the problem to be solved by the group online (where students can explore various possibilities within the group by actively contributing to the group);
Helping learners to build up knowledge base of relevant facts about the problem to be solved online (where students can begin to integrate their ideas to influence others within their group);
The newly acquired knowledge is shared by the group online with the aim of solving the given problem collaboratively and collectively (where students can resolve issues relating to the assigned work to be completed collectively);
Delivering various artifacts leading to a solution or a number of solutions to the problem to be solved online (where students can integrate and resolve the problem to be solved collectively).
Garrison, Anderson, and Archer’s (2001) definition and use of trigger, exploration, integration, and resolution within their Practical Inquiry model is in line with SQUAD approach usage of these same terms. We have empirically validated the SQUAD approach at message level with an established framework called the Practical Inquiry model for assessing cognitive presence of CMC discourse (Oriogun, Ravenscroft and Cook, 2005). We adopted the alignments suggested by one of the developers of the Transcript Analysis Tool (Fahy, 2002) at sentence level to assess students’ cognitive engagement within online groups. The SQUAD is a semi-structured way of categorising online messages. The SQUAD approach to CMC discourse invites students to post messages based on five given categories, namely, Suggestion, Question, Unclassified, Answer and Delivery (Oriogun, 2003b).
The Study
The case study used to validate the TRCP inter-rater reliability method is from a course titled Software Engineering for Computer Science that the author teaches at London Metropolitan University. In the first academic semester of 2005–06, 23 students completed the course.
Table 1
Group2 SQUAD Statistics
(Group and Individual SQUAD Contribution) Semester 1 -2005/06
Student No | S | Q | U | A | D | TOTAL |
Student 1 | 27 | 7 | 4 | 9 | 12 | 59 |
Student 2 | 14 | 6 | 4 | 6 | 8 | 38 |
Student 3 | 6 | 0 | 1 | 4 | 5 | 16 |
Student 4 | 3 | 3 | 2 | 2 | 2 | 12 |
Student 5 | 8 | 1 | 0 | 2 | 6 | 17 |
TOTAL | 58 | 17 | 11 | 23 | 33 | 142 |
The students were split randomly into 4 coursework groups (Groups 1-4). Groups 1 and 2 consist of 5 members each, Groups 3 had 6 members and Group 4 was composed of 7 members. Each group had a designated Tutorial Assistant (TA). Each group negotiated their software requirements online using the SQUAD software prototype (Oriogun and Ramsay, 2005) to facilitate their online contributions over a period of 12 weeks comprising the semester.
The author randomly selected Group 2 SQUAD statistics as a case study for the purpose of this experiment. Table 1 shows the final SQUAD statistics for Group 2 at the end of the semester. The associated online learning levels of engagement (Oriogun, 2003b) of each student is shown in Table 2:
Table 2
Group 2 SQUAD Online Learning Levels of Engagement
Student | High (%) | Nominal (%) | Low (%) |
Student 1 | 66 | 15 | 18 |
Student 2 | 57 | 15 | 26 |
Student 3 | 68 | 25 | 6 |
Student 4 | 41 | 16 | 41 |
Student 5 | 82 | 11 | 5 |
The purpose of this study is to use the TRCP inter-rater reliability method to clean a group of software engineering students’ online transcripts before measuring their levels of engagement with respect to participation and interaction. Once this has been established, the author will then use SQUAD results applying TAT alignments as proposed by (Oriogun, Ravenscroft and Cook 2005, pp205-210) to measure the same group’s online group engagement using the phases of the Practical Inquiry model as a framework. In the first semester of 2005/06, five students were asked to be second coders (or raters) of their own individual transcripts using data generated through the statistics compiled from the SQUAD software environment (see Table 1). It is expected that results obtained from such content analysis should be consistent with the students’ online learning levels of engagement for each student as shown in Table 2.
Table 3
Coding Decisions Based on Message Ratings
(Oriogun, 2003a; Oriogun and Cook, 2003)
Rating | |
No engagement with the group | 0 |
Agreeing with others without reasons | 1 |
Agreeing with others with reasons | 2 |
Referring the group to relevant Web sites | 3 |
Resolving conflicts within the group | 4 |
Taking a lead role in discussion | 5 |
Offering to deliver artifact(s) | 6 |
Offering alternative solutions to group problems | 7 |
Active engagement with the group | 8 |
The group chosen for this study posted 142 messages among its five students from 12th October 2005 until 11th January 2006 (92 days). The author extracted all the messages from this group in order to investigate the quality of each student’s participation and interaction using message (Marttunen 1997, 1998; Ahern, Peck, and Laycock 1992) as a unit of analysis, where each message is objectively identified before producing a manageable set of cases that incorporates problem-based learning (Woods 2000; Oriogun et al., 2002) activities before categorization as documented in Table 3. It took a total of 5hours 45minutes to print the 142 transcripts and generate the initial TRCP values for all the transcripts as shown in Table 4. This exercise was conducted between 8th February 2006 and 15th February 2006 inclusive.
The TRCP Approach
After carefully reading each of the 142 messages, the author coded them (see Table 4 for the ‘unclean’ transcripts) using the criteria set out in Table 3. Each student was then rated according to the two variables being investigated, namely, participation and integration (see Table 5 for detail). Each student was asked to rate his or her own individual transcripts, generated when they used the SQUAD approach to negotiate software requirements online as a group in the first semester of 2005/06 (see Table 1).
Table 4
Coded Online Message Transcripts with Initial TRCP Values
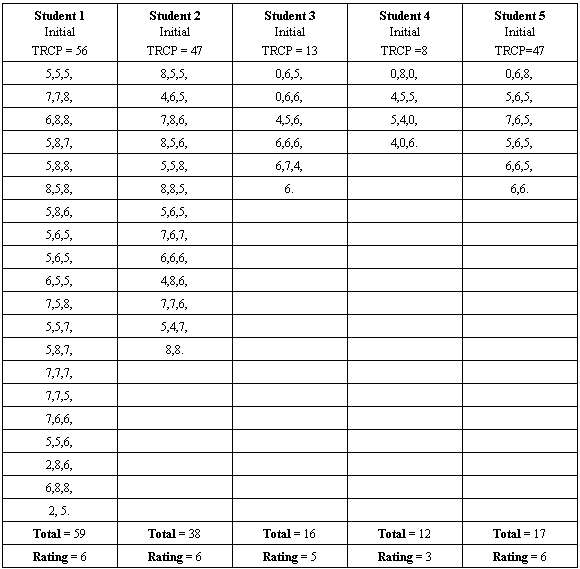
The student coders (raters) also had access to the details in Table 3, as well as their individual transcripts from Table 1. Each student coder (rater) sought clarification from the author with respect to the rationale behind the categories of message ratings, and to fully understand his intention before generating their own set of ratings.
Table 5
Category of Final Student’s Rating and Variables Investigated
(Oriogun and Cook, 2003)
Variables Investigated | Unit of Analysis (Message) | Final Rating Category* |
None | No engagement with the group | LLE |
Participation, Interaction | Agreeing with others without reasons | LLE |
Participation, Interaction | Agreeing with others with reasons | LLE |
Participation, Interaction | Referring the group to relevant Web sites | MLE |
Participation, Interaction | Resolving conflicts within the group | MLE |
Participation, Interaction | Taking a lead role in discussion | MLE |
Participation, Interaction | Offering to deliver artefact(s) | HLE |
Participation, Interaction | Offering alternative solutions to group problems | HLE |
Participation, Interaction | Active engagement with the group | HLE |
* MLE = Low Level Engagement, LLE = Medium Level Engagement, HLE = High Level Engagement
It was not the duty of the student coders (raters) to convince the author to change his mind about the coding decisions. Once the student coders (raters) were satisfied that they understood the intentions behind each coding decision in Table 3, they rated the transcript independently, and eventually built their own compilation of ratings before the final TRCP was calculated (see Table 6).
Inter-rater Reliability Measure
Holsti (1969) provided the simplest and most common method of reporting inter-rater reliability —coefficient of reliability (C.R.)—as a percentage agreement statistic. The formula is
C.R. = 2m / n1 - n2
where: m= the number of coding decisions upon which the two coders agree
n1 = number of coding decisions made by rater 1
n2 = number of coding decisions made by rater 2
Cohen’s kappa (1960), on the other hand, is a statistic that assesses inter-judge agreement for nominally coded data. It can be applied at both the global level (i.e., for the coding system as a whole) and the local level (i.e., for individual categories). In either case, the formula is
kappa = (F0 - FC) / (N - FC)
where: N = the total number of judgements made by each coder
F0 = the number of judgements on which the coders agree
FC = the number of judgements for which agreement is expected by chance
A number of statisticians characterize inter-judge agreement as inadequate, as it does not account for chance agreement among raters (Capozzoli, McSweeney, and Sinha 1999). Therefore, with respect to Cohen’s kappa (1960), Capozzoli, McSweeney, and Sinha suggest that:
… values greater than 0.75 or so may be taken to represent excellent agreement beyond chance, values below 0.40 or so may be taken to represent poor agreement beyond chance, and values between 0.40 and 0.75 may be taken to represent fair to good agreement beyond chance.(6)
Cleaning the Transcripts
In line with Capozzoli, McSweeney, and Sinha suggestion (Oriogun and Cook, 2003; pp227-228) further suggest that:
“…if the initial percentage agreement is greater than or equal to 70%, the transcript is deemed to be “clean.” In this case, the initial TRCP was the same as the final TRCP. Otherwise, a final TRCP should be calculated before the transcript can be considered to be “clean” and adequate given the subjectivity of such scoring criteria. The kappa value (Cohen 1960) should be calculated from the clean transcript with a final TRCP.”
Table 6
Coded Online Message Transcripts with Final TRCP Values
Student 1
TRCP =100 Kappa = 1.0 F0 = 59 FC = 18 N = 59 | Student 2
TRCP =100 Kappa =1.0 F0 = 38 FC = 16 N = 38 | Student 3 Final
TRCP =100 Kappa =1.0 F0 = 16 FC = 7 N = 16 | Student 4
TRCP=100 Kappa = 1.0 F0 = 12 FC = 11 N = 12 | Student 5
TRCP=100 F0 = 17 FC = 8 N = 17 |
| 5,5,5 | 5,5,5 | 0,6,8 | 0,5,8 | 8,6,8 |
| 4,7,8 | 4,4,8 | 2,6,4 | 8,6,6 | 5,6,7 |
| 6,6,5 | 5,8,8 | 8,5,6 | 8,5,8 | 3,6,6 |
| 5,8,5 | 8,5,8 | 6,7,6 | 5,8,6 | 5,6,6 |
| 5,8,8 | 5,5,8 | 6,4,4 | 8,6,8 | |
| 8,8,5 | 8,8,5 | 8. | 6,6. | |
| 5,5,6 | 5,6,8 | |||
| 5,6,4 | 6,5,7 | |||
| 5,6,5 | 6,6,6 | |||
| 6,5,5 | 8,6,6 | |||
| 5,5,2 | 7,5,6 | |||
| 5,5,5 | 8,8,8 | |||
| 5,5,7 | 8,8. | |||
| 7,7,7 | ||||
| 2,5,5 | ||||
| 6,6,6 | ||||
| 5,5,6 | ||||
| 1,8,6 | ||||
| 6,8,6 | ||||
| 1,5. | ||||
| Total = 59 | Total = 38 | Total = 16 | Total = 12 | Total = 17 |
| Rating = 6 | Rating = 6 | Rating = 5 | Rating = 6 | Rating = 6 |
The author invited the five students to the university on 17th February 2006 in order for each of them to rate their own transcripts before he calculated the initial TRCP values as shown in Table 4. Currently, Table 4 contains ‘unclean’ transcripts (Oriogun and Cook 2003, pp226-227). The author supplied the students with the coding decisions based on message ratings in Table 3, and told them that he has already used these categories to rate their SQUAD posted messages recently after they had completed their studies for the module, Software Engineering for Computer Science during the first semester of 2005/06.
The author further explained the rationale behind each coding decision, and asked the students not to confuse themselves while rating their own online transcripts by thinking of the SQUAD approach to online discourse. When he was happy that all the students understood the intentions behind the coding scheme in Table 3, they were asked to individually rate their own transcripts. It took a total of 2hours 55 minutes to finalise the rating of all 142 online message transcripts after discussion by the two raters (students acted as second raters of their own transcripts as shown in Table 1, the author acted as the first rater of each of the students transcripts) in order to generate the final TRCP value of 100, and a Kappa value of 1.0 for each student’s transcripts on 17th February 2006 as shown in Table 6.
Once the transcripts has been ‘cleaned’ using the TRCP inter-rater reliability method, the author used the phases of the Practical Inquiry model (triggers, exploration, integration and resolution) to realise the cognitive engagement of Group 2. Table 7 below shows the comparison of the phases of the Practical Inquiry model with the present Fahy (2005) Practical Inquiry / TAT results and Group 2 SQUAD results applying TAT alignments (Oriogun, Ravenscroft and Cook 2005, pp205-210). See the concluding section for the analysis of Table 7.
Table 7
Comparison of Phases of the Practical Inquiry Model With the Present
Fahy (2005) Practical Inquiry/TAT Results and Group 2 SQUAD /TAT Alignments
(Semester 1 –2005/06)
Phases of the practical Inquiry Model | Practical Inquiry Model Results, Garrison, Anderson, and Archer (2001) Initial Pilot |
Practical Inquiry Model Results, Fahy (2005) Present Study |
TAT Results, Fahy (2005) | SQUAD Results Applying TAT Alignments SQUAD #1 Oriogun, Ravenscroft, and Cook (2005) | SQUAD Results Applying TAT Alignments SQUAD #2 Oriogun, Ravenscroft, and Cook (2005) | SQUAD Results Applying TAT Alignments SQUAD #3 Oriogun, Ravenscroft, and Cook (2005) |
Triggers | 12.5 | 9.4 | 6.4 | 11.8 | 28.2 | 28.2 |
Exploration | 62.5 | 74.2 | 76.4 | 48.6 | 7.7 | 48.6 |
Integration | 18.8 | 14.6 | 14.6 | 57.0 | 64.1 | 64.1 |
Resolution | 6.3 | 1.8 | 2.5 | 64.1 | 64.1 | 40.1 |
Interpretation of Results
It took Student 1 a total of 20 minutes to rate his own 59 messages (it took the author a total of 30 minutes to rate the same set of messages as depicted in Table 4 above). After Student 1 completed his rating, it took a further 30 minutes for both of us to agree on the final TRCP value of 100 in Table 6 and to generate the final ‘Rating’ value of 6. In total, Student 1 online transcripts rating by both coders took a total of 40 minutes to finalise.
It took Student 2 a total of 25 minutes to rate his own 38 messages (it took the author a total of 22 minutes to rate the same set of messages as depicted in Table 4 above). After Student 2 completed his rating, it took a further 22 minutes for both of us to agree on the final TRCP value of 100 in Table 6 and to generate the final ‘Rating’ value of 6. In total, Student 2 online transcripts rating by both coders took a total of 47 minutes to finalise.
It took Student 3 a total of 13 minutes to rate his own 16 messages (it took the author a total of 4 minutes to rate the same set of messages as depicted in Table 4 above). After Student 3 completed his rating, it took a further 30 minutes for both of us to agree on the final TRCP value of 100 in Table 6 and to generate the final ‘Rating’ value of 5. In total, Student 3 online transcripts rating by both coders took a total of 43 minutes to finalise.
It took Student 4 a total 7 minutes to rate her own 12 messages (it took the author a total of 3 minutes to rate the same set of messages as depicted in Table 4 above). After Student 4 completed his rating, it took a further 9 minutes for both of us to agree on the final TRCP value of 100 in Table 6 and to generate the final ‘Rating’ value of 6. In total, Student 4 online transcripts rating by both coders took a total of 16 minutes to finalise.
It took Student 5 a total 7 minutes to rate his own 17 messages (it took the author a total of 5 minutes to rate the same set of messages as depicted in Table 4 above). After Student 5 completed his rating, it took a further 12 minutes for both of us to agree on the final TRCP value of 100 in Table 6 and to generate the final ‘Rating’ value of 6. In total, Student 5 online transcripts rating by both coders took a total of 19 minutes to finalise. Table 8 shows some of the actual messages sent by members of Group 2 under the S category of the SQUAD framework. See Appendix for these messages.
Table 8
Examples of Online Discourse for Final Transcript Reliability Cleaning Percentage (TRCP) Transcript
Message Number | Student number | Final TRCP Rating |
31 | 1 | 5 |
4 | 2 | 4 |
3 | 3 | 8 |
2 | 4 | 5 |
7 | 5 | 3 |
Discussion
It took 5 hours and 45 minutes for the author to generate the initial ‘unclean’ TRCP transcripts. It took a further 2hours 55 minutes to generate the final ‘clean’ TRCP transcripts and the associated TRCP value together with the Kappa value for comparison after discussion with each student involved in this study. In total, it therefore took 8hours 40 minutes to complete this study. This is the reason why quantitative content analysis of computer transcripts is time consuming. In my previous study (Oriogun and Cook 2003; p230) it took 11 hours to finalise the coded transcripts by just two raters. This is the reason why few researchers using quantitative content analysis of computer transcripts have published results derived from a second content analysis.
TRCP inter-rater reliability method measures online participation and interaction. As the author is validating the TRCP method within the SQUAD framework (a semi-structure approach to online discourse), the expectation from this experiment was that the students would have participated and interacted within their group effectively. This has been borne out from this experiment. Although, the initial TRCP ratings for three of the students was ‘High Level Engagement’ (Student 1, Student 2 and student 5 all scored an initial TRCP of 6 with the unclean transcripts), one of the student’s (Student 3 score an initial TRCP of 5) rating was ‘Medium Level Engagement’, and finally, Student 4 scored the lowest as far as the unclean transcripts was concerned, making the students rating ‘Low Level Engagement’.
Conclusion
The final TRCP ratings confirms that when using a semi-structured approach to online transcripts as a framework to calculating students’ online levels of engagement with respect to variables participation and integration, students engagement are expected to be relatively high. The author realised in the final ‘clean’ transcripts that indeed, four of the five students in this study had scored ‘High Level Engagement’ (namely, Student 1, Student 2, Student 4 and Student 5). Student 3 remains at ‘Medium Level Engagement’ (see Table 6).
The fact that these five students had worked under the SQUAD framework, a semi-structured approach to online discourse before this exercise, during the formulation of the final TRCP values, the students became the owner of their own transcripts, and were able to articulate the meaning and intentions behind each of their messages. This is in fact why in the final TRCP values for each of the students was indeed 100%.
In effect, the roles stipulated for first and second raters of the transcripts initially by the author has been reversed, indeed, during the discussion of the transcripts, the author found himself to be agreeing with all the students. Recently the author read an article on inter-rater reliability Wilson Cockburn and Halligan, P (1987), where authors of the article reported that 100% inter-rater reliability was achieved in their study. The author was rather surprised at this particular finding, however, the empirical study presented in this article appear to support their claim.
The Practical Inquiry (PI) model initial pilot results (Garrison, Anderson and Archer 2001), the present Fahy (2005) PI model results and Fahy (2005) current TAT results all indicate that exploration was clearly the most common type of posting. The TAT result and the initial PI model results showed that the next most common type of posting was integration. The SQUAD results however showed on average that integration was the most common posting, followed closely by resolution, this was followed by exploration and finally triggers. The reason for this could be because the SQUAD is already a semi-structured approach to online discourse, and students’ contribution was already scaffold during the semester. Indeed, this was why the students took ownership of their transcripts during the ‘cleaning’ of their individual transcripts, as they are already very much aware of their own messages and the meaning attached to the same. This also plays an important role in having achieved TRCP of 100% and Kappa value of 1.0 during the cleaning of each of the student’s transcripts.
It is also possible that because the PI model and the TAT alignments are still operating at the inter-rater reliability level of granularity, whilst the SQUAD approach operates at a slightly higher level of reasoning by already scaffolding software engineering students online postings, contribute to the better results exhibited by SQUAD in comparison to the PI model and the TAT alignments.
References
Ahern, T., K. Peck, and M. Laycock, M. 1992. The effects of teacher discourse in computer-mediated discussion. Journal of Educational Computing Research 8 (3): 291–309.
Anderson, T., Rourke, L., Garrison, D. R., & Archer, W (2001). Assessing Teaching Presence in a Computer Conference Context. Journal of Asynchronous Learning Networks, 5(2), 2001, ISSN 1092-8235. [Online]: http://www.sloan-c.org/publications/jaln/v5n2/v5n2_anderson.asp [viewed 1st March 2006]
Barrows, H. (1996). Problem-based learning in medicine and beyond: A brief overview. In L. Wilkerson and W. Gijselaers (Eds), Bringing Problem-Based Learning to Higher Education: Theory and Practice. New Directions for Teaching and Learning, 68, 3-11. San Francisco: Jossey-bass Publishers.
Bridges, E. M. (1992). Problem-based learning for administrators. ERIC Clearing House, University of Oregon.
Capozzoli, M., L. McSweeney, and D. Sinha. 1999. Beyond kappa: A review of interrater agreement measures. The Canadian Journal of Statistics 27 (1): 3–23.
Cohen, J. (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurements, 20, 37-46.
Fahy, P. J., Crawford, G., Ally, M., Cookson, P., Keller, V. & Prosser, F. (2000). The development and testing of a tool for analysis of computer mediated conferencing transcripts. Alberta Journal of Education Research, 46(1), 85-88.
Fahy, P. J. (2001). Addressing some common problems in transcript analysis, International Review of Research in Open and Distance Learning, 1(2) 2001. http://www.irrodl.org/content/v1.2/research.html#Fahy [viewed 24 Mar 2003, verified 18 Sep 2003]
Fahy, P.J. (2002). Assessing critical thinking processes in a computer conference. Centre for Distance Education, Athabasca University, Athabasca, Canada. Unpublished manuscript. Available online at http://cde.athabasca.ca/softeva/reports/mag4.pdf
Fahy, P. J. (2005). Two Methods for Assessing Critical Thinking in Computer-Mediated Communications (CMC) Transcripts, International Journal of Instructional Technology and Distance Education, 2 (3) 2005. http://www.itdl.org/Journal/Mar_05/article02.htm [viewed 1st March 2006]
Garrison, R., T. Anderson, and W. Archer (2001). Critical thinking, cognitive presence, and computer conferencing in distance education. American Journal of Distance Education 15 (1): 115-152.
Hara, N., Bonk, C. & Angeli, C. (2000). Content analysis of online discussion in an applied educational psychology course. Instructional Science, 28(2), 115-152.
Henri, F. (1992). Computer conferencing and content analysis. In A. Kaye (Ed), Collaborative learning through computer conferencing: The Najaden papers, pp 117-136. London: Springer-Verlag.
Holsti, O. 1969. Content analysis for social sciences and humanities. Don Mills: Addison-Wesley Publishing Company. Working Knowledge Productive Learning at Work, International Conference, The Research into Adult and Vocational Learning Group, University of Technology at Sydney, New South Wales, Australia.
Hutton & Wiesenberg, (2000). Quality online participation: Learning in CMC classroom. RCVET Working Knowledge Conference Papers. Research Centre for Vocational Education and Training, University of Technology, Sydney, Australia, 10-13 Dec 2000. [viewed Mar 2003, verified 18 Sep 2003] http://www.rcvet.uts.edu.au/wkconference/working%20knowledge64.pdf
Marttunen, M. 1997. Electronic mail as a pedagogical delivery system. Research in Higher Education 38 (3): 345–363.
McDonald, J. (1998). Interpersonal group dynamics and development in computer conferencing: The rest of the story. In Proceedings of 14th Annual Conference on Distance Teaching and Learning, pp. 243-48. Madison, WI: University of Wisconsin-Madison [ERIC Document ED422864]
Oriogun, P. K., French, F. & Haynes, R. (2002). Using the enhanced Problem-Based Learning Grid: Three multimedia case studies. In A. Williamson, C. Gunn, A. Young & T. Clear (Eds), Winds of Change in the Sea of Learning: Proceedings of the ASCILITE Conference. Auckland, New Zealand: UNITEC Institute of Technology, 8-11 December 2002, pp495-504. http://www.ascilite.org.au/conferences/auckland02/proceedings/papers/040.pdf
Oriogun, P. K. (2003a). Content analysis of online inter-rater reliability using the transcript reliability cleaning percentage: A software engineering case study. Presented at the ICEIS 2003 Conference, Angers, France, 23-26 April 2003, pp.296-307, ISBN 972-98816-1-8.
Oriogun P. K (2003b)."Towards understanding online learning levels of engagement using the SQUAD approach. Australian Journal of Educational Technology, 19(3), 371-388. http://www.ascilite.org.au/ajet/ajet19/ajet19.html
Oriogun and Cook (2003). “Transcript Reliability Cleaning Percentage: An Alternative Interrater Measure of Message Transcripts in Online Learning”, The American Journal of Distance Education, ,17(4) 221-234, Lawrence Erlbaum Associates, Inc.
Oriogun P. K and Ramsay E (2005). "Introducing a dedicated prototype application tool for measuring students’ online learning levels of engagement in a problem-based learning context", Proceedings, The IASTED International Conference on Education and Technology, ICET 2005, Calgary, Canada, July 4-6, 2005, pp 329-334, CD-ROM ISBN 0-88986-489-6, Book ISBN 0-88986-487-X.
Oriogun P K, Ravenscroft A and Cook J (2005). "Validating an Approach to Examining Cognitive Engagement within Online Groups", American Journal of Distance Education, ISSN 0892-3647, volume 19(4), 197-214, December 2005.
Piaget, J (1928). “Judgement and reasoning in the child”, New York: Harcourt Brace, 1928.
Rourke, L. & Anderson, T. (2004). ‘Validity issues in quantitative computer conference transcript analysis’, Educational Technology Research and Development 52(1) 5-18.
Wilson B, Cockburn, J and Halligan, P (1987). “Development of a behavioral test of visuospatial neglect”, Archive of physical medicine and rehabilitation, 1987 Feb; 68(2): 98-102
http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?cmd=Retrieve&db=PubMed&list_uids=3813864&dopt=Citation [viewed 27the February 2005].
Weiss, R. & Morrison, G. (1998). Evaluation of a graduate seminar conducted by listserv. [ERIC Document Reproduction Service, ED 423868]
Zhu, E. (1996). Meaning negotiation, knowledge construction, and mentoring in a distance learning course. In Proceedings of Selected Research and Development Presentations at the 1996 National Convention of the Association for Educational Communications and Technology (18th, Indianapolis, IN). Available from ERIC documents: ED397849.
Appendix
Messages Sent by Students
Student 1 Message 31
S-Student 3(Normalization + Process Model) – Student 1
Sun Nov 20 11:02:00 GMT 2005
I saw your Normalization + Process model picture which are great. You need to change our ERD to reflect with your process model, which I find more complete. However! I think you need to read just your normalisation. First we don't need customer details. One more, start with unnormalised set of data, then go to Normalisation 1 then 2 then you reach to level 3 which you have done.. Okie?? Before I forgot, please can you change the data in our zip database? What you need to change is in the Order Details table we have got Transaction date. Please can you change all 2003 into 2005 and keep the date and month. Okie? Cheers |
Student 2 Message 4
S-TASK 2 – Student 2
Wed Oct 19 13:39:54 BST 2005
Firstly, there’s a bit about operational policies (policies on audit trails, copyright protection, etc), we haven't discussed that at all, so I have no idea what to put there. Secondly, Operational stakeholders is very similar to effects of operations, since I’m basically writing the stakeholders involved, and how they interact etc, so I only had that under effects of operations. And finally, redressal of current system shortfalls. We haven't talked about the proposed system, how it will be, what it will involve, so I don't know what to write for that. Only thing we know are the stakeholders. But we never went further than that to discuss how or what the proposed system would be like. Ok, I think that's a lot of reading.. but basically, at the end of the day, we can't just keep going away like this and do tasks one after the other when the middle, or the end isn't clear. I don't know about the rest of you, but its like we're just trying to push along, without discussing how it's going to plan out at the end. Any comments would be appreciated. |
Student 3 Message 3
S-Important reading about winwin – Student 3
Fri Oct 14 23:38:22 BST 2005
Regards |
Student 4 Message 2
S-Left members of the group – Student 4
Fri Oct 21 12:15:20 BST 2005
Some of us have already left the group and I don't know the name of them except Student X. Since we have to inform Peter how many people we need to replace asap, please post the name of the people who's left. I am sending emails to everyone in case those people who are already left won't see the SQUAD. |
Student 5 Message 7
S-Lab – Student 5
Wed Nov 09 05:51:45 GMT 2005
Student 5 |
About the Author
Peter Oriogun | Peter Oriogun is currently a Senior Lecturer in Software Engineering at London Metropolitan University. He is the Course Director of the MSc Computing programme offered by London Metropolitan University. His current research interests are in semi-structured approaches to online learning, CMC transcript analysis, software life cycle process models, problem-based learning in computing and cognitive engagement in online learning. He is a chartered member of the British Computer Society. He has over 20 years teaching experience in software engineering, computing and online collaborative learning within Further and Higher education institutions in the UK, and has extensive publication in this area of expertise. The title of his PhD thesis by prior output is “Towards understanding and improving the process of small group collaborative learning in software engineering education”. Peter K Oriogun Email: p.Oriogun@londonmet.ac.uk Tel: +44 0207 133 7065 |
