| January 2010 Index | Home Page |
Editor’s Note: This study traces individual activities to study learning patterns and identify successful patterns to enhance learning effectiveness in future learning environments.
Automatic Update of e-Learning Environments Based on Heterogeneous Traces
Henda Chorfi and Belhassen Guettat
Tunisia
Abstract
In e-learning environments, collecting data on users from their activities traces is crucial. It permits improvement of the adaptation process and the development of pedagogical tools. Modeling users in an e-learning environment is well researched. Nevertheless, sharing and reusing user data jointly in different environments is still overlooked. In this context, the question that arises is: How to systematically update different environments after activities performed by a user in a given environment? In this paper, this question is addressed and a solution is proposed. It updates systematically diverse models of different environments based on the activities performed by a user in a given environment.Keywords: ILE; heterogeneous traces; interaction; SBHT; user model, repository, e-learning environment.
Introduction
In e-learning environments, collecting data on users from their activities traces is crucial. It permits improvement of the adaptation process and the development of pedagogical tools. Modeling users in an e-learning environment is largely studied in research [1],[2],[3]. Nevertheless, sharing and reusing user data jointly in different environments is yet overlooked. Indeed, we face obstacles such as: the technical characteristics of each environment, lack of interaction between different environments, difficulty of managing heterogeneous traces, inconsistency in some environments, etc. In this perspective we distinguish different end-users and different situations of reusing and sharing data.
First, we can consider the learner who pursues a course on an environment E1 and wants to continue his training in an environment E2. What happens? Simply, the learner must repeat all the steps already undertaken in the environment E1, and thereafter he could continue his training. Indeed, there is no trace in the second environment which can update his model and estimate the degree of progress of the learner!
Second, we consider the tutor who responds to learners requests in an environment E. Those interactions can be exploited by the rest of the environments to help improve the learners in similar situations.
To summarize, the question that arises is: How to systematically update different environments based on the activities performed by a user in a given environment?
To answer this question, we have to consider how to deal with heterogeneous traces (collected about the user in different environments) in order to update different heterogeneous learning environments. The difficulty is that the activity performed by a user in a given environment is represented by a trace having specific format and semantics. In this context, we propose a solution that systematically updates diverse models of different environments after the activities performed by a user in a given environment.
The paper is structured as follows: Section 2 explores a synthesis of research about the learning environments. We focus on systems based on traces and principally on systems based on heterogeneous traces. Section 3 discusses the various alternatives to address the issues mentioned above. In the next section, the solution is developed. The architectural, the conceptual and the technical aspects are detailed. Finally, a conclusion is presented in which we summarize what we have done and we discuss other aspects that remain to be done.
Synthesis on Systems Based on Traces
We began by giving an overview on Interactive Learning Environments (ILE) and their evolution, subsequently we focus on systems based on traces: a comparative study has been developed which has led to a System Based on Heterogeneous Traces (SBHT).
Brief Overview on ILE
The Interactive Learning Environment (ILE) is dealing with the environments designed in order to "foster human learning, ie the construction of knowledge among learners" [4]. Studying these environments has allowed us to identify the essential specifications that ILE should provide:
First, the ILE must capitalize and integrate learning resources which it disseminates, being regularly fed and operated by teachers. The latter can create, put and update their educational resources with a view of all the lessons (better integration and coordination).
It must be pedagogically adapted to needs of students, identified and grouped according to different profiles.
It must be generic, i.e. built as a configurable container and help the contextualization of the content being able to accommodate diverse educational content, developed with the most commonly used tools.
However, these environments are often specific to the used tool and have several limitations such as the lack of interaction control between the trainer and the learner, the difficulty of re-learning of the training scenarios, the problems with the re-use, the low operating of the concept of trace in the modeling scenario. Therefore, these types of ILE evolved into Systems Based Traces (SBT). In the context of ILE, the concept of trace can mean either the historic of learner’s interactions using an ILE or the productions the learner left during his training.
ILE Based on Traces
We have identified three categories of learning systems based on traces: the quantitative environments (based on log files), the proprietary environments (specific) and the environments based on models (SBT). The existing approaches of trace management that are based on the log files have to face some barriers relating to the access and the meaning of information:
§ They are contained in files that are not generally available to any user.
§ They do not transcribe the real exploitation of the system by the users.
§ The acquisition of these data must be made according to an interval of time determined by the system´s supervisor and not real-time.
§ The information, contained in these files, is not always very accurate.
These drawbacks could be remedied by approaches which provide observation mechanisms specific to a particular learning tool: For example, Application eMediathèque[1] of eLycée is an interactive and collaborative work tool that aims to improve reflexive activities during a collaborative learning [5].
If the approaches which are specific to a particular tool have some strengths that fill gaps in approaches based on log files (acquisition and visualization of traces in real time, traces collected in function of user activity, precise and detailed information), they suffer from their partitioning and of their owner aspects. The traces collected by these systems have a specific format that prevents their processing by other SBT. On the other hand, traces are contained within a specific system and can not be reused. The review of different approaches leads us to propose a System Based on Heterogeneous Trace (SBHT) that incorporates the benefits of specific approaches, and fills their gaps.
Such system must be able to:
§ collect heterogeneous traces and their models in a single repository through action reification mechanism to be able to share and reuse them.
§ represent dynamically the effective activities of the learner, whether in terms of operating procedures, or of information searches using the collected traces.
§ instantiate, from the repository, for each type of educational activity, a professional trace whose semantics is the activity it represents.
§ chart in real time and in an exhaustive way all activities of the learner and visualize, in an interactive manner, the traces thereon.
§ perform basic operations on these traces like sorting elements they contain, clustering, filtering, and displaying properties or entities (the visual masks).
§ make easy the use of the ILE technologies for teachers, helping them to develop learning strategies from learning profiles and to customize different learning systems.
§ allow a user to operate multiple environments with a systematic upgrading of the latter.
Proposed Solutions
System Architecture
The specifications above permit us to conceive the architecture of the proposed SBHT [Figure 1]. Based on the standards imposed by the DMTF (Distributed Management Task Force), including concept mapping CIM (Common Information Language) [6], we developed a generic model of traces that can represent user activities within learning systems based on heterogeneous traces [7]. In this paper, we zoom on the framed part to respond at the following questions: i.e. how can the traces be collected and transformed? What are the options to update the different ILE from our repository traces?
It is therefore necessary to propose solutions that can systematically update the different models from different environments after the activities performed by a user in a given environment.
Two solutions can be envisaged, the first is to find a unified model for all traces issued from any environment and stored in the repository of traces; the second permits storage of all the traces and their models in a repository and relate them; when any activity is triggered, all models involved are given and therefore the related environments will be updated.
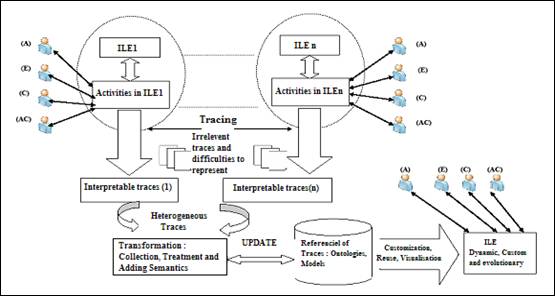
Figure 1. Architecture of the SBHT
First Solution : Unified Trace
The SBHT based on a distributed and multi-component architecture (Figure 2), will be conform with specifications detailed in [8]. We have several environments distributed on what activities were performed by different users: Learning (A), Teacher (E), Designer (C) and Research Analyst (AC). For each activity, a trace will be saved. This gives us for each environment a set of traces with different qualities and natures: incomplete, irrelevant, relevant, interpretable, and so on. Each trace environment must be analyzed and processed, using its modeling tools, to produce and implement the end modeled traces on which semantics have been added. If we denote by (E) the environment, (M) the application model on the trace and (TM) obtained modeled traces, we can represent the system (S) by S = ((E) (M) (TM)). It is clear that systems from different learning environments are not similar, especially at the level of representation model traces. So, we have at the end heterogeneous models and traces. Then, the questions that we can ask are:
From an environment how, one might use, reuse, or benefit from activities transformed in modeled traces? How can we customize the course of a user in an environment by operating the previous experiments performed on different systems?
It is therefore necessary to find a solution that can gather these traces and models in one repository able to standardize traces independently of semantic and specific technology of environments. This is the purpose of our SBHT. As input, it must be possible to store heterogeneous modeled traces and their models in a single repository, which is an intelligent system capable of representing the information and relationships that can exist between them. It looks like a Knowledge Base System (KBS) for which we must find a Knowledge Base (Traces Base) and a database containing models and ontologies of traces (Models Base). The interaction between these bases is essential to meet the needs of users. From these resources, our SBHT must have a generalized interface 'a kind of middleware' that will accept in input of the traces and their models and produce traces represented semantically in a standard model (Pivot Model). This is the highlight of this system. We can then generate a consistent traces database. However, the feedback will be difficult: How can update environments Ei from the repository traces?
Here, it will be more difficult: we must find inverse functions to convert a unified trace into a modeled trace imposed by the environmental issue. That is why we moved to the second solution.
Second Solution : Related user models
1) Presentation: The same assumptions will be considered and the same process is used at least initially. Each trace environment must be analyzed and processed, using its modeling tools, to produce and implement the end modeled traces on which semantics have been added. If we denote by (E) the environment, (M) the application model on the trace and (TM) obtained modeled traces, we can represent the system (S) by S = ((E) (M) (TM)). As input, our SBHT must be able to store heterogeneous modeled traces and their models in a single repository: it is an intelligent system capable of representing the information and relationships that can exist between-them. The interactions between models are needed to meet the needs of users on the one hand, and to ensure the consistency and integrity of the repository, on the other hand. In this case, if a user accesses an environment to perform an activity, the system will be able to update all environments affected by this activity. Technically, it develops a component (Services), from a model invoked by a user when he is oing an activity; this component must be able to update systematically the traces models stored in the repository (sequential scan of all models).
When the repository is updated, we must ensure the consistency of dealing environments; in which case our system must include a component that, from any model of the repository, you must be able to access it in the corresponding environment and update it (Figure 2).
2. Description: This architecture consists of four levels: the first level concerns the learning environments (ILE i), the second tier is related with the models and the traces of ILE i (Tmi model), the third level is dealing with services (Smi) which is the plate rotating system; it provides several features: control and trade. The final level is the repository of traces that form the core of this system. In the following, we will detail each level.
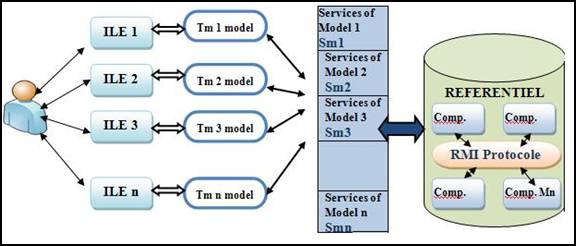
Figure 2. Architecture of the second solution (2)
ILE Level (ILE i) : This level concerned the learning environments (ILE) that the user can exploit. The latter, for learning, can access various environments. There are different types of users: learners, tutors, designers and researchers. Each ILE is mainly characterized by activities traces and their semantics.
Models Level (Tmi) : By accessing one or more ILE, a user will carry out activities; each one will leave a gross trace that will be modeled according to the belonging environment. The Tmi component consists on transforming activity of an environment Ei, in to modeled trace (Tmi). This way, if a user operates on an Environment Ei, it will be saved by his Tmi. The basic functionality of this component is to filter all traces (not that any traces will undergo a conversion) and leave only the traces activities that are comprehensive and relevant. Thereafter, these traces will undergo changes depending on the traces model supported by the belonging environment.
Services Level (Smi) : When processed, the activities traces must be injected with their models in the traces repository. This is the first part flowing from that business component. In a second step, the components (Smi) must update the model (mi) from an activity represented by a model (TMj). In fact, for each user model (input), it should systematically invoke all the other repository components and update those who are concerned. This component is a composition unit with specific interfaces; it can be deployed independently and can also communicate with another component Smj through a protocol such as RMI. It is therefore the hub of our system.
Repository Level:This is the system kernel. It contains all models and all traces from different learning environments. It is organized into components (Comp Mi): each one contains all of the different users’ models and must be compatible with the models obtained in models Level (Tmi), to allow the update and ensure consistency and integrity of information in the repository. To do this, we must have management system components (Comp. Mi) as a “Data Base Management System (DBMS)”, which will allow them to relate them in a relational schema. In that case, if we have an activity performed by a user in a given environment, and represented by its model Mi, and based on the relational schema, the Smi will be able to update the corresponding models Mj. For what is the protocol that will ensure communication between the components (Comp. Mi) of the repository, we should not worry about it; protocol RMI (Remote Method Invocation) might do the trick: It is a programming interface (API) which allows the calling of remote methods. Using this API requires the use of an RMI registry on the remote machine hosting the registered objects we wish to call. This programming interface is very often used in conjunction with the JNDI directory, API, or with the specification of transactional distributed components EJB in Java language (in the Services Level Smi, we must also provide a JNDI directory service) [8]. It is a technology that enables communication via the HTTP protocol between Java objects physically distant from each other, ie running on distinct Java virtual machines.
RMI fosters the development of distributed applications by hiding the developer communication between client and server. As shown, the system management models (Comp. Mi) performs the same tasks as those of a DBMS: consistency and data integrity, provide mechanisms and tools update, ensure the availability information, define integrity constraints between database objects (in our case the relations between the components Mi), make transactions from the repository to update another application (in our context, update to the ILE from components Mi updated), and so on.
3) Simplified Algorithm:
The user accesses to an environment to perform an activity (Ei).
A user model will be generated Tmi (Tmi means that an activity trace is generated by the supported environmental Ei model (Tmi).
Smi services will then be triggered: we start by injecting the Tmi in component (Comp. Mi), then each Smi will updates the component Mi from a model Mj generated by the user. In that case, we will have all components Mi updated.
The services Smi must subsequently complete the feed-back, each service (Smi) must update the corresponding ILEi. We will have at the end and, as expected, the different ILEi updated.
4) The Conceptual Schema Repository:
Based on the work of Broisin and Vidal (SIERA-IRIT Toulouse) [9] and the standards imposed by the DMTF including concept mapping CIM (Common Information Language), a generic model is developed (Figure 3) capable of representing heterogeneous trace user activities within the repository [10].
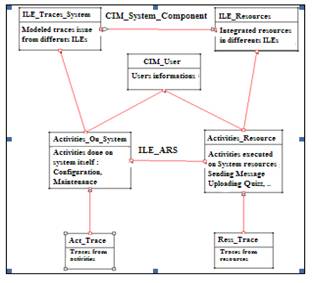
Figure 3. Generic Model of the SBHT
Conclusion
In this article, we address the question: How to update systematically different models of different environments after the activities performed by a user in a given environment? First; we give an overview on the Interactive Learning Environments (ILE) based generally on traces and especially on heterogeneous traces. To answer our initial question, we present two solutions. Then, we detailed the retained solution after explaining the problems of the first solution especially when we want to update the ILE Level after updating their models in repository. For the retained solution, we explain each component of the architecture, specifying the algorithm of our system and presenting the conceptual model of the data repository according to the CIM approach considered one of the standards DMTF. The prototype is under development: we chose the J2EE platform for developing: it’s an architecture based on distributed multi-component and its tools are open source.
References
[1] Kavcic, A. The Role of User Models in Adaptive Hypermedia Systems. Proceedings of the 10thMediterranean Electrotechnical Conference MEleCon 2000, May, Lemesos, Cyprus.
[2] Martins, A. C., Faria, L., Vaz de Carvalho, C., & Carrapatoso, E. (2008). User Modeling in Adaptive Hypermedia Educational Systems. Educational Technology & Society, 11 (1), 194-207.
[3] Brusilovsky, P. (1996a). Methods and techniques of adaptive hypermedia. User Modeling and User-Adapted Interaction, 6 (2-3), 87-129.
[4] Tchounikine P., " Pour une ingénierie des Environnements Informatiques pour l’Apprentissage Humain", Revue I3 : "information – interaction – intelligence 2(1)", 2002.
[5] eLycée, "Teaching Method", elycee.com/elycee-campus/, 2007.
[6] DMTF: Distributed Management Task Force: Common Information Model (CIM) Specification, Technical support, DSP0004, pp. 96, 1999.
[7] Guettat B., Chorfi H., Jemni M., "Customized Learning Environment Based on Heterogeneous Traces", IEEE-IC4E’2010, Sanya, China, 2010.
[8] Printz J., "Architecture Logicielle – Concevoir des applications simples, sûres et adaptables", Edition Dunod, 2006.
[9] Broisin J., Vidal P., "Une approche conduite par les modèles pour le traçage des activités des utilisateurs dans des EIAH hétérogènes", Journal Sticef, volume 14, 2007.
[10] Guettat B., Chorfi H., Jemni M, " Heterogeneous-Traces Based adaptation of e-learning activities in a distributed environment", IEEE-CSEDU’2010, Valencia, Espagna, 2010.
About the Authors
Henda Chorfi and Belhassen Guettat are from the Research Unit of Technologies of Information and Communication (UTIC), High School of Sciences and Techniques of Tunis, Tunisia
Belhassen.guettat@isetr.rnu.tn
End Note:
[1] eMédiathèque: Application developed by a young company eLycée offering to francophone students, enrolled to learn French language and culture.